오늘 첫 시작은 현직자 특강 세미나를 들었습니다.
모두의 연구소 대표님이 직접 진행해 주셨고 AI에 대해 알아가는 시간이었습니다.
이렇게 직접 듣고 이야기해보며 느끼는 점은 빠르게 지나가는 시간처럼 발전 또한 빠르게 진행된다는 점이었습니다.
저도 뒤처지지 않기 위해 제 스스로를 앞으로 더 발전시키는 것이 매우 중요하다고 생각이 들었어요.
그 후에는 머신러닝에 대해 배워보았습니다.
이전 교육을 들었을 때 가장 어려워했었던 부분이 머신러닝과 딥러닝인데 결국 다시 만나게 되었습니다.. ㅜuㅜ...
피할 수 없으면 즐기라고 하듯이 결국엔 어려운 것도 돌파하고 즐겨야 하지 않나 싶습니다.
그리고 그게 또 개발의 매력이니까요 '3'
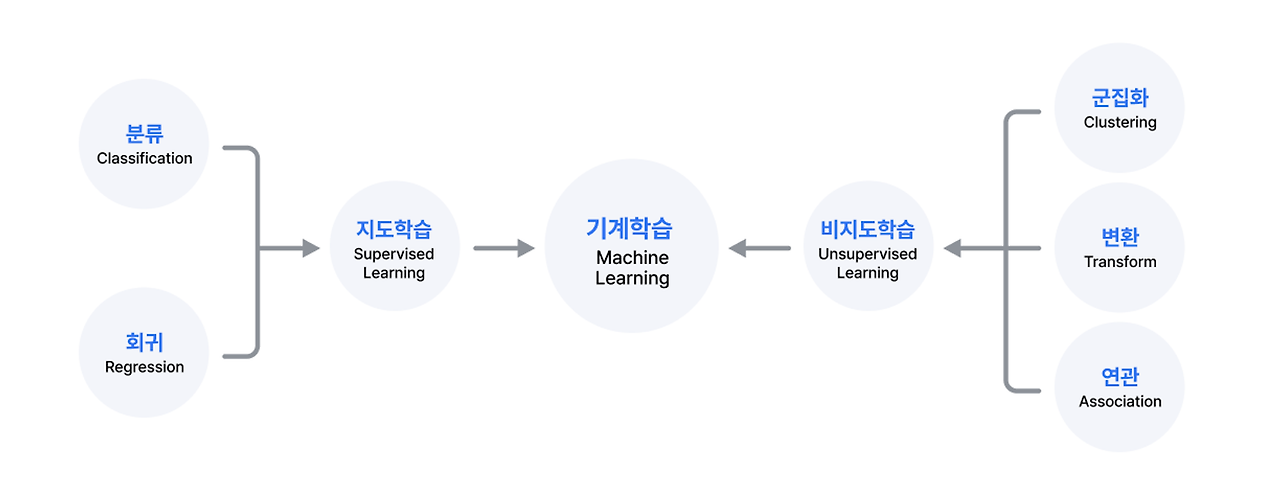
머신러닝 (Machine Learning)
인공지능(Artificial Intelligence, AI)의 한 분야
데이터 안에서 패턴(규칙)을 찾아내어 학습하고 결과를 예측하는 분석 방법
지도학습(Supervised Learning), 비지도학습(Unsupervised Learning), 강화학습(Reinforcement Learning)으로 분류
+ 데이터 마이닝(Data Mining), 예측 분석(Predictive Analytics), 패턴 인식(Pattern Recognition) 등 다양한 분야에서 활용
지도학습 (Supervised Learning)
입력 데이터와 출력(정답) 데이터가 존재하는 경우 사용
훈련 데이터(입, 출력 데이터)
= 입력 값(X data)이 주어지면 입력값에 대한 정답(라벨 :Y data)을 데이터에서 지정해주어야 함
+ 대표적인 알고리즘
1. K-최근접 이웃 (K-Nearest Neighbors)
2. 선형 회귀 (Linear Ragression)
3. 로지스틱 회귀 (Logistic Regression)
4. 서포트 벡터 머신 (Support Vector Machine, SVM)
5. 의사 결정 나무 (Decision Tree)와 랜덤 포레스트(Random Forest)
6. 신경망 (Neural Networks)
분류 (Classification) 그리고 회귀 (Regression)
이진 분류 : 입력값에 따라 모델이 분류한 카테고리가 두 가지인 분류 알고리즘
= 어떤 대상에 대한 규칙이 참(True)인지 거짓(False)인지를 분류
다중 분류 : 입력값에 따라 모델이 분류한 카테고리가 세 가지 이상인 분류 알고리즘
회귀 : 어떤 데이터들의 특징(feature)을 토대로 값을 예측
= 주어진 입력 변수와 출력 변수(예측하려는 변수) 사이의 관계를 모델링하는 기술

비지도학습 (Unsupervised Learning)
출력(정답) 데이터가 존재하지 않는 경우 사용
비슷한 특징끼리 훈련을 통해 군집화하여 새로운 데이터에 대한 결과를 예측하는 방법
모델이 입력 데이터를 학습한 다음, 관련성이 있고 학습 가능한 데이터를 모두 사용해 패턴과 상관관계를 인식
1. 비지도 학습은 사람이 세상을 관찰하는 방식을 기반으로 다양하게 모델링
2. 사람은 직관과 경험에 의존해 사물을 그룹화
3. 어떤 사물에 대해 경험하는 예시의 수가 많을수록 그것을 분류하고 인식하는 능력이 더욱더 정확해짐
+ 대표적인 알고리즘
1. 군집화 (Clustering)
2. 시각화와 차원 축소 (Visualization & Dimensionality reduction)
3. 연관 규칙 학습 (Association rule learning)

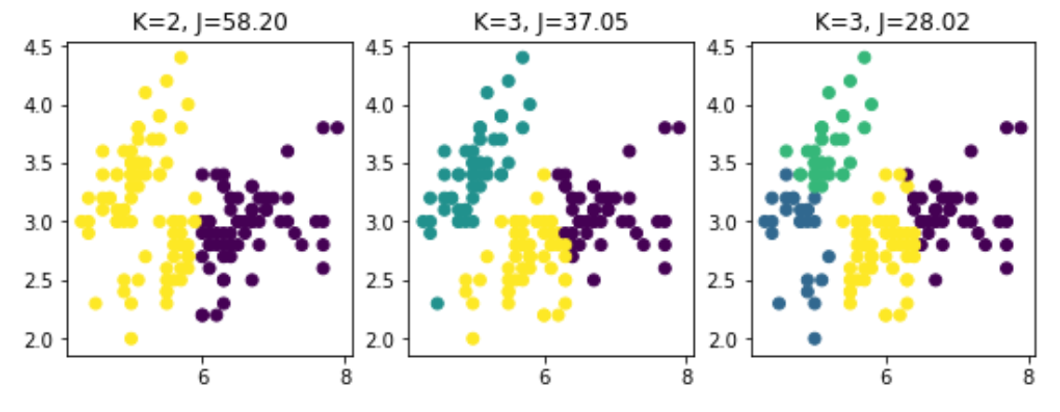



군집화 (Clustering)
서로 유사한 정도에 따라 다수의 객체를 군집으로 나누는 작업 또는 이에 기반한 분석을 의미
1. 유사도가 높은 데이터끼리 그룹화 (대표적으로 유클리드 거리식 이용)
2. 계층형 클러스터링과 비계층형 클러스터링으로 분류
+ 대표적인 알고리즘
1. k-평균 (k-means)
2. DBSCAN
3. 계층 군집 분석 (Hierarchical Cluster Analysis, HCA)
4. 원-클래스 서포트 벡터 머신 (One-class SVM)
5. 아이솔레이션 포레스트 (solation Forest)

강화학습(Reinforcement Learning)
시행착오를 통해 보상을 최대화하는 방향으로 학습하는 방법
= 보상(Reward)이라는 개념을 사용하여 가중치와 편향을 학습하는 것
ex) 게임의 실력을 키워가는 과정
1. 게임을 조작하기 위해, 게이머는 자신의 캐릭터와 장애물을 확인
2. 플레이를 통해 장애물을 넘어가면 점수를 주고 장애물에 부딪히면 점수를 뺏김
3. 관찰에 따라 장애물을 넘을지 게이머가 판단
4. 플레이를 하는 동안 장애물을 극복하기 위해 판단과 실행을 반복
5. 판단력이 강화될수록 점수는 높아짐
6. 게임을 하는 실행과정은 게임에 변화를 주게 되며 게이머가 점점 실력자가 되는 과정

준지도 학습(Semi-Supervised Learning)
지도학습과 비지도학습의 사이에 있는 학습 방법
레이블이 존재하는 데이터와 존재하지 않는 데이터를 모두 훈련에 사용하는 것
+ 대표적인 알고리즘
1. 심층 신뢰 신경망 (Deep belief networks, DBN)
(제한된 볼츠만 머신(Restricted Boltzmann machine, RBM)을 기반으로 순차적으로 학습한 후, 지도 학습 방식으로 세밀하게 조정)

머신러닝 개발 순서
1. 데이터 import
= CSV 파일 읽기, 함수 호출해서 읽기, ZIP 파일로 압축한 파일 읽기, API 호출 (한글이 깨지는 경우 인코딩해줄 것)
2. 데이터 확인
= display 함수 or describe 함수를 활용해서 전체적인 데이터를 활용
(산점도를 그려보고, 결측치, 평균, 분산 같은 수치들을 변수별로 추출)
3. 데이터 전처리
= 누락값이나 이상치는 처리해야 함, 모델이 학습 안 될 경우를 고려
4. 데이터 분할

5. 알고리즘 선택
= Sklearn이나 XGBoost 등을 활용 (라이브러리 내장 함수 사용)
6. 학습
= fit 함수를 사용하여 모델을 학습
7. 예측
= 정확도를 평가하기 위해 학습 후 원본 데이터와 비교
8. 평가
= 평가에 의해 다시 처음 단계로 돌아갈 수 있음
9. 튜닝
= 파라미터의 조정으로 올라갈 수 있는 범위는 제한됨, 빠른 시간 안에 주어진 자원 내에서 튜닝을 빠르게 시도할 것
알고리즘을 재선택하거나 파라미터 조정, 특징값 최적화 등 다양한 방법론을 사용 (데이터 사이언티스트의 고유 영역)
+ 머신러닝 프로세스
1. 가설 설정
2. 탐색적 데이터 분석 (EDA)
3. 베이스라인 모델 구축
4. 성능 개선
+ 머신러닝과 AI의 상관관계
AI는 의사결정과 예측을 수행하기 위해 데이터를 처리
= 머신러닝 알고리즘으로 데이터를 처리할 뿐 아니라 추가 프로그래밍 없이도 데이터를 학습하면서 지능화함
따라서 AI는 모든 머신러닝 관련 하위 집합을 포괄하는 상위집합
첫 번째 하위집합은 머신러닝, 그 안에 딥러닝, 딥러닝 안에는 신경망

선형회귀분석 (Linear Regression Analysis)
독립변수와 종속변수가 선형적인 관련성이 있다는 전제하에, 변수들 간의 관계를 선형 함수식으로 모형화하기 위한 분석방법
= 독립변수(X)와 종속변수(Y) 사이의 선형적 관계를 찾는 방법
Y = β0 + β1X + ε
# β0는 절편(intercept) / β1은 기울기(slope) / ε은 오차항(error term)
+ 최소제곱법 (Least Squares Method)
실제 값과 예측 값의 차이인 잔차(residual)의 제곱합을 최소화하는 방법으로 회귀선을 찾음



성능 평가 및 해석


로지스틱 회귀 (Logistic Regression)
독립 변수의 선형 결합을 이용하여 사건의 발생 가능성을 예측하는 데 사용되는 통계 기법
종속 변수가 범주형 데이터를 대상으로 함
= 입력 데이터가 주어졌을 때 해당 데이터의 결과가 특정 분류로 나뉘기 때문에 일종의 분류(classification) 기법
ex) 데이터가 특정 범주에 속할 확률을 예측
1. 모든 속성(feature)들의 계수(coefficient)와 절편(intercept)을 0으로 초기화
2. 각 속성들의 값(value)에 계수(coefficient)를 곱해서 log-odds를 구함
3. log-odds를 sigmoid 함수에 넣어서 [0, 1] 범위의 확률을 구함
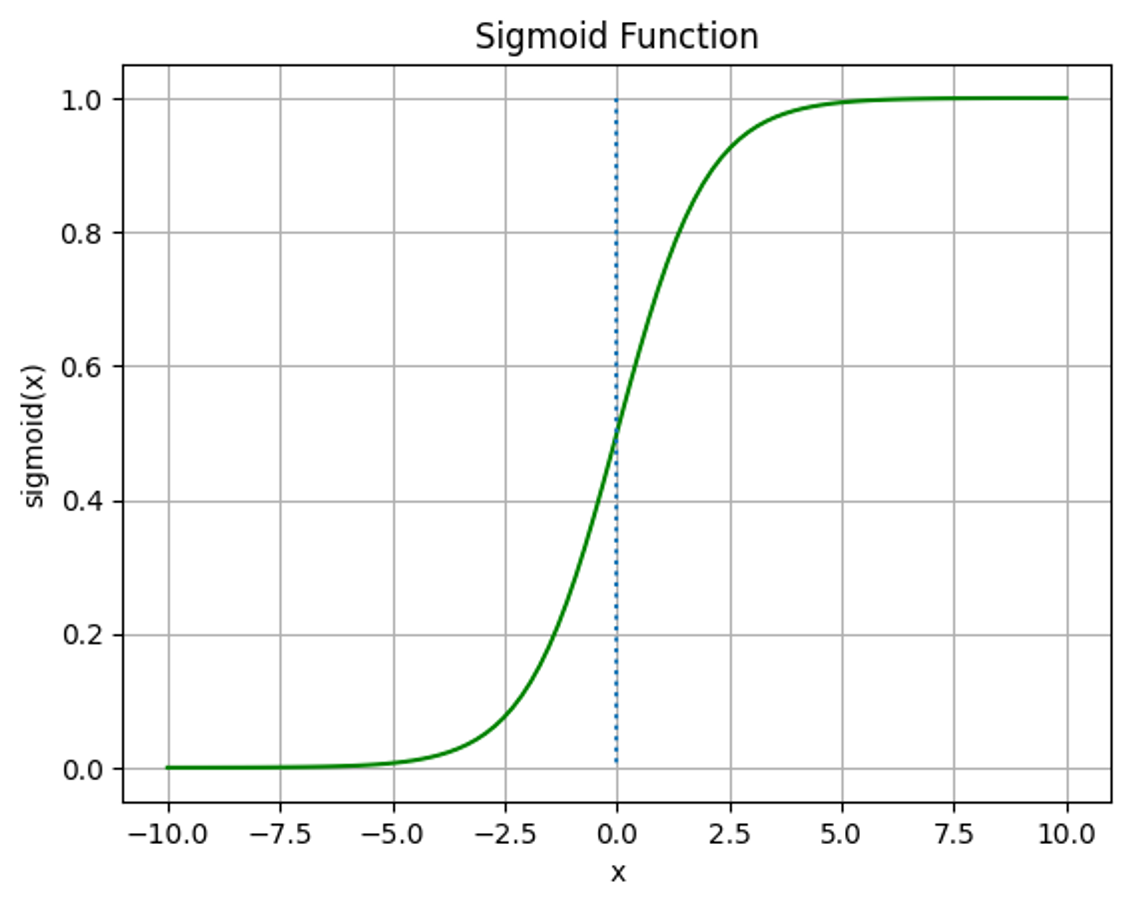
+ 시그모이드 함수 (Sigmoid Function)
S자형 곡선 또는 시그모이드 곡선을 갖는 수학 함수
데이터가 클래스에 속할지 말지 결정할 확률 컷오프를 임계값(Threshold)이라 함
기본 값은 0.5이지만 데이터의 특성이나 상황에 따라 조정 가능
로지스틱 회귀모델은 파라미터()를 학습하기 위해 최대 우도 추정법(Maximum Likelihood Estimation)을 사용
최대 우도 추정법이란 Likelihood Function을 최대로 하는 파라미터()를 찾는 것
로지스틱 회귀 모델 해석
1. 회귀 계수 : 회귀 모델의 파라미터 ()를 뜻함
회귀 계수가 양수 : 해당 회귀계수에 해당하는 독립변수가 증가하면 성공할 확률이 증가
회귀 계수가 음수 : 해당 회귀계수에 해당하는 독립변수가 증가하면 성공할 확률이 감소
2. 승산 비율 : 나머지 입력변수는 모두 고정시킨 상태에서 한 변수를 1 단위 증가시켰을 때 변화하는 Odds의 비율
이 1단위 증가하면 성공에 대한 승산비가 만큼 변하게 됨
가 1보다 크다 = 가 1보다 크다 = 가 0보다 크다 (즉, 회귀 계수가 양수)
가 1보다 작다 = 가 1보다 작다 = 가 0보다 크다 (즉, 회귀 계수가 음수)
기분 탓일까요..
역대급으로 글과 사진이 많이 올라가는 듯 한 느낌입니다... ;)
문제는 제 GitHub에서 참고해 주세요!
관련 파일이랑 같이 commit 되어 있습니다.
https://github.com/soohyun020812/ormcamp
GitHub - soohyun020812/ormcamp: 오름캠프 교육에서 활용한 실습 내용들 정리
오름캠프 교육에서 활용한 실습 내용들 정리. Contribute to soohyun020812/ormcamp development by creating an account on GitHub.
github.com